In this tutorial i want to show you how to add the scraped data from scrapy crawler to a MongoDB database. For this we will use the scrapy crawler pipeline with the correct connection to a localhost server.
This tutorial will walk you through these tasks:
In this Scrapy project I scrape quotes from https://quotes.toscrape.com/
- Creating a new Scrapy project
- Setting up the Database connection and spider items.
- Writing a spider to crawl a site and extract data
- Exporting the scraped data using the pipeline to a MongoDB database collection
Install Scrapy if dont already have it installed.
pip install scrapyBefore you start scraping, you will have to set up a new Scrapy project. Enter a directory where you’d like to store your code and run:
scrapy startproject mongodbtutorial
This will create a tutorial directory with the following contents:
mongodbtutorial/
scrapy.cfg # deploy configuration file
tutorial/ # project's Python module, you'll import your code from here
__init__.py
items.py # project items definition file
middlewares.py # project middlewares file
pipelines.py # project pipelines file
settings.py # project settings file
spiders/ # a directory where you'll later put your spiders
__init__.py
Now you have created a new project and in this step you need to set up the database credentials. For this step open the file mongodbtutorial –> settings.py and add following code to your settings file.
MONGO_SERVER = "127.0.0.1". # server ip adress
MONGO_PORT = 27017. # port of mongodb connection
MONGO_DB = "quotes". # name of the database
MONGODB_COLLECTION = "quotes" # name of your mongodb collectionAnd below the sentences in settings.py you need also configure the Item pipeline:
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'mongodbtutorial.pipelines.MongodbtutorialPipeline': 600,
'mongodbtutorial.pipelines.MongoDBPipeline': 600,
}and enable the spider middleware:
SPIDER_MIDDLEWARES = {
'mongodbtutorial.middlewares.MongodbtutorialSpiderMiddleware': 543,
}after this changes in settings.py, you need to prepare your pipeline file under mongodbtutorial –> pipeline.py
at first import a few libraries and define your pipeline:
from logging import log
import scrapy
from pymongo import MongoClient
from scrapy import settings
from scrapy.exceptions import DropItem
# useful for handling different item types with a single interface
from itemadapter import ItemAdapteradd a new class named MongoDBPipeline below the class MongodbtutorialPipeline in pipeline.
class MongoDBPipeline(object):
def __init__(self):
connection = MongoClient()
connection = MongoClient('localhost', 27017)
db = connection.quotes
self.collection = db['quotes']
def process_item(self, item, spider):
for data in item:
if not data:
raise DropItem("Missing data!")
self.collection.replace_one({'url': item['url']}, dict(item), upsert=True)
log.msg("Quote added to MongoDB collection!",
level=log.DEBUG, spider=spider)
return item
And now you need define your items in items.py with the field names on your collection.
class MongodbtutorialItem(scrapy.Item):
text = scrapy.Field()
author = scrapy.Field()
tags = scrapy.Field()then run the following code to run your the spider
scrapy crawl quotesand now we have all the quotes in our database collection:
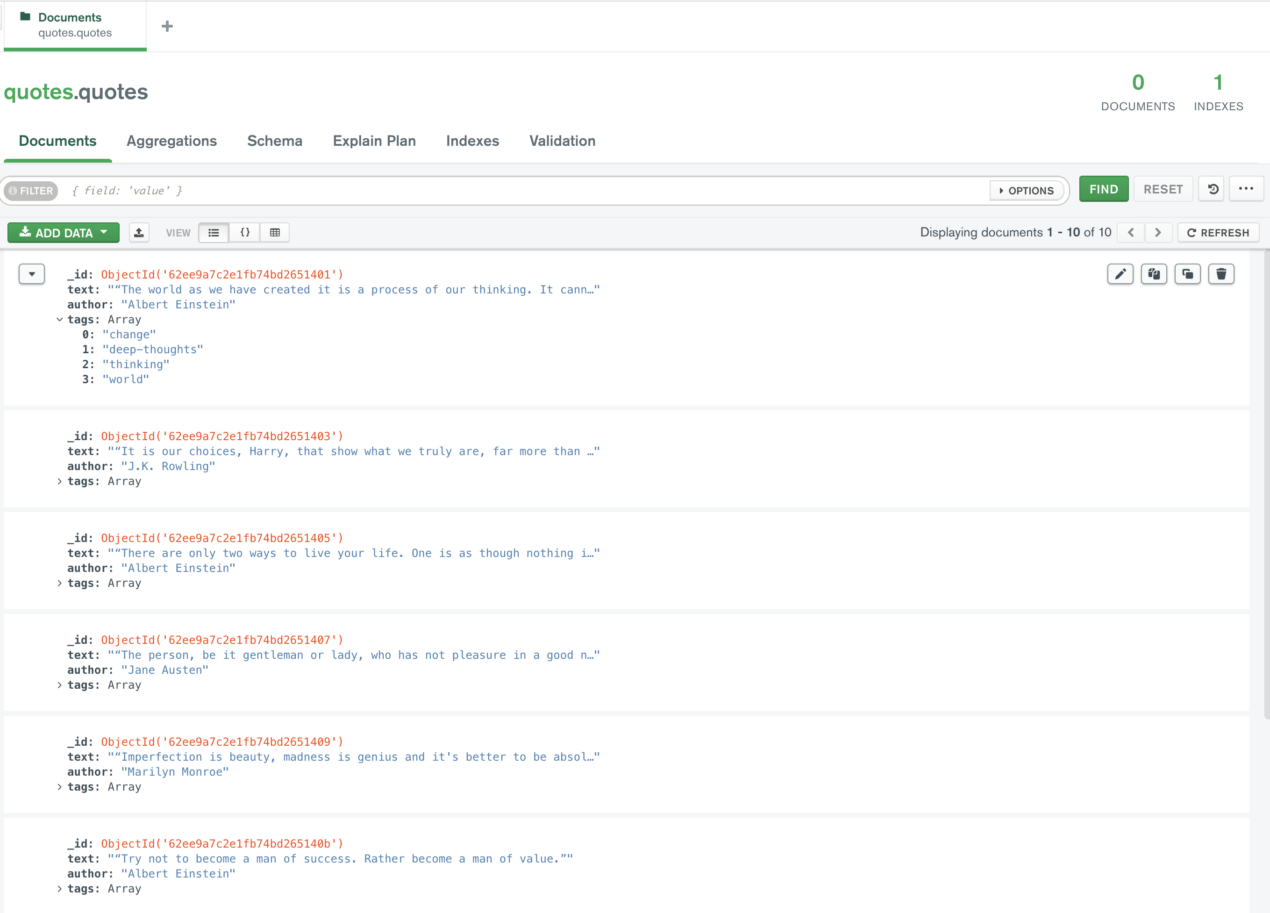
Extracted data:
{
'text': '“A day without sunshine is like, you know, night.”',
'author': 'Steve Martin',
'tags': ['humor', 'obvious', 'simile']
}