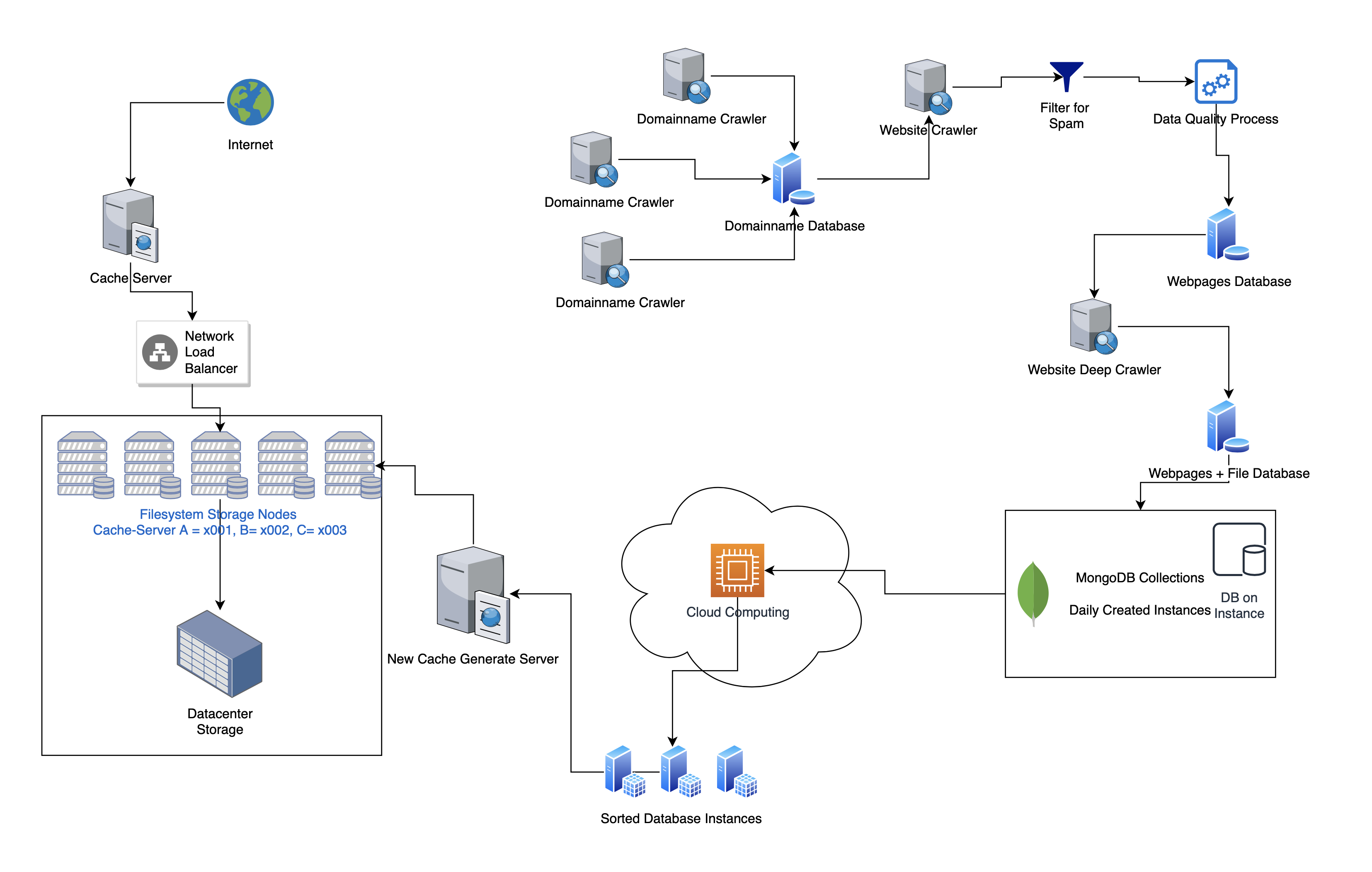
Web Scraping with Scrapy pipeline to add crawled data to MongoDB collection [Tutorial]
In this tutorial i want to show you how to add the scraped data from scrapy crawler to a MongoDB database. For this we will use the scrapy crawler pipeline with the correct connection to a localhost server. This tutorial will walk you through these tasks: In this Scrapy project I scrape quotes from https://quotes.toscrape.com/ … Read more