“There are only two hard things in Computer Science: cache invalidation and naming things”
Phil Karlton
on my last post from 30 March 2022, I started with same crawlers to finding unique hostnames and then collecting them on a mysql database. Example Crawler:
dcrawl – searches hostnames from given start url. A free open-source project for collecting huge of domain names. written in Golang and easy to use.
I build a new Project with scrapy to scrap data from a valid hostname with the status code 200, and exporting Data to a pipeline, after checking the data for duplicates, sending data to inserting to the collection on mongodb as an Object, which will be used on the 3rd Step to computing and sorting the Data with given sorting–algorithm for given “query“.
“Good code is its own best documentation. As you’re about to add a comment, ask yourself, ‘ How can I improve the code so that this comment isn’t needed?’ “
Steven C. McConnell
An example of indexed url:
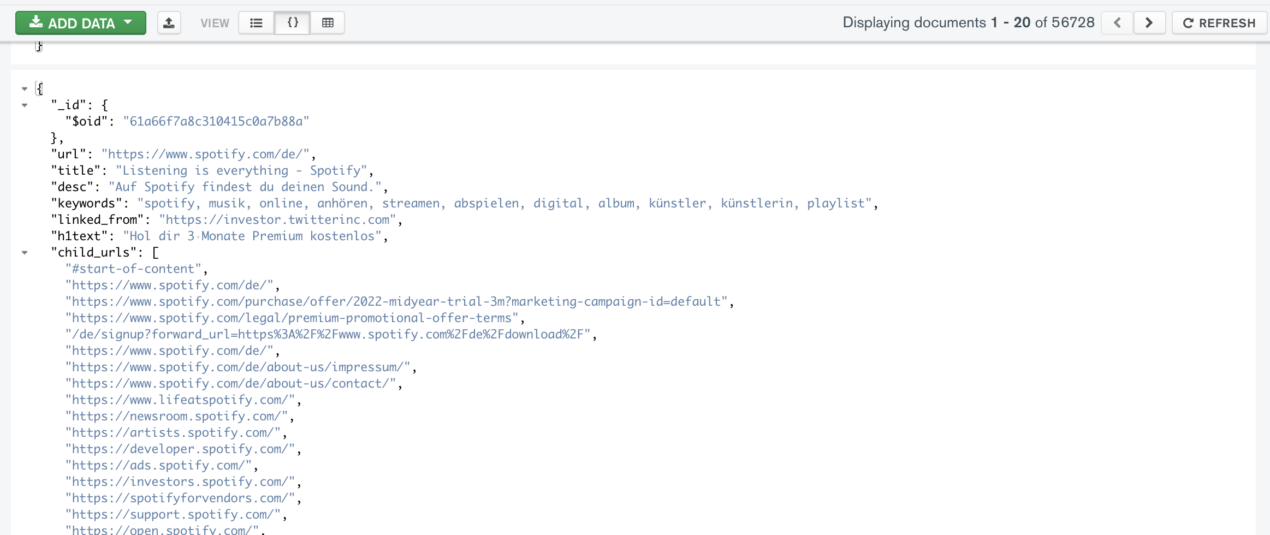
The crawler gets also the child_urls and the information about the source of given object(linked_from).
As next Step:
– Building the system on a cloud with more computing resources.
– Building a MongoDB as a Instance with multiple instances(Cluster-Database).
– Get input, compute and output. Starting to writing a sorting algorithm with corpus of a text. In this case is our text = the meta-data of indexed title, description, keywords and also the count of in and outgoing links and also a source of own Object (url).
“You cannot manage that which you cannot measure”
James Love Barksdale, CEO of Netscape
On way:
count of collected unique hostnames: 13.745.841 domains
count of indexed valid hostnames(just the start-pages): 56.728 domains
last update: 3th May 2022
Which Language and which Repo for Crawling?
A collection of awesome web crawler,spider and resources in different languages
Awasome-Crawler GitHub: https://github.com/BruceDone/awesome-crawler