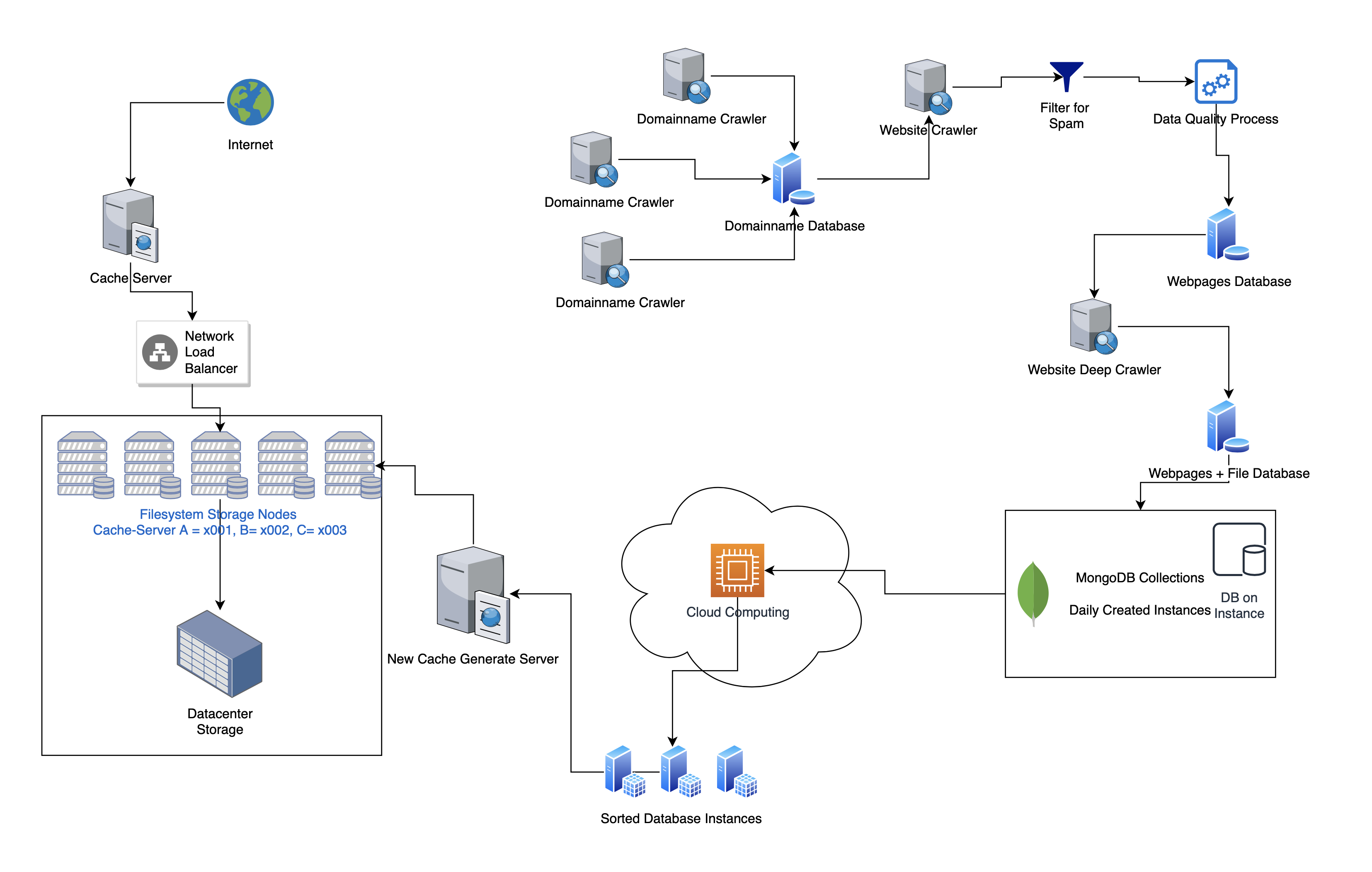
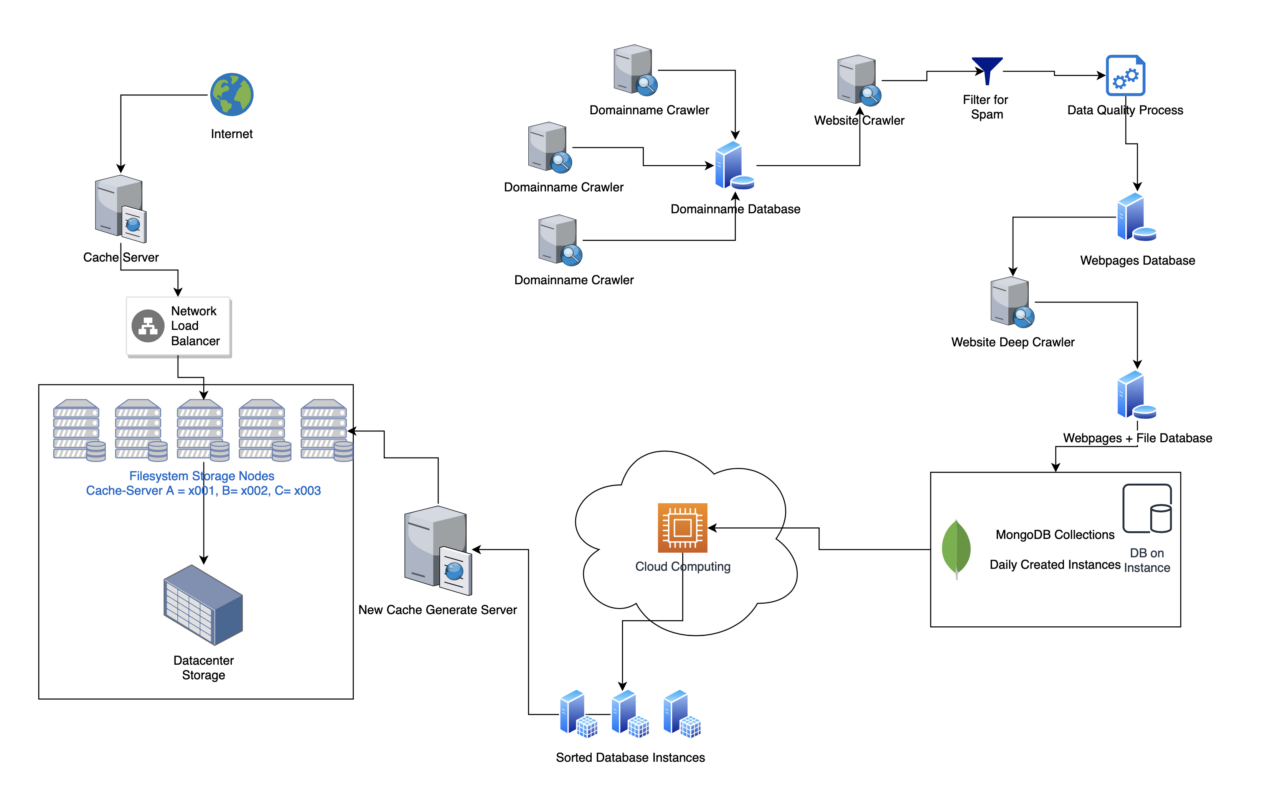
This article is currently being revised and expanded!
Last update on 01.07.2022: getting more then 100 Million of unique domain name on a MySQL Database.
Using MeiliSearch for indexing is cool, but after 10 Million Index it will be very slow to indexing new rows.
Because of this I am looking for a faster way to indexing all the urls.
“The amateur software engineer is always in search of magic”
Grady Booch, father of UML
In this article we will are planing to build a search engine with Laravel 9, Python 3 and MongoDB. Using the Laravel Scout Package and MongoDB for Backend and also MySQL on some cases. And PHP Framework Laravel for the Frontend and Backend User Interface Pages.
Frist of all, we need an Enterprise Architecture(EA) and of course an Enterprise Architecture Management (EAM). In following image you can see the Relationship between enterprise architecture, service-oriented architecture and the cloud computing.
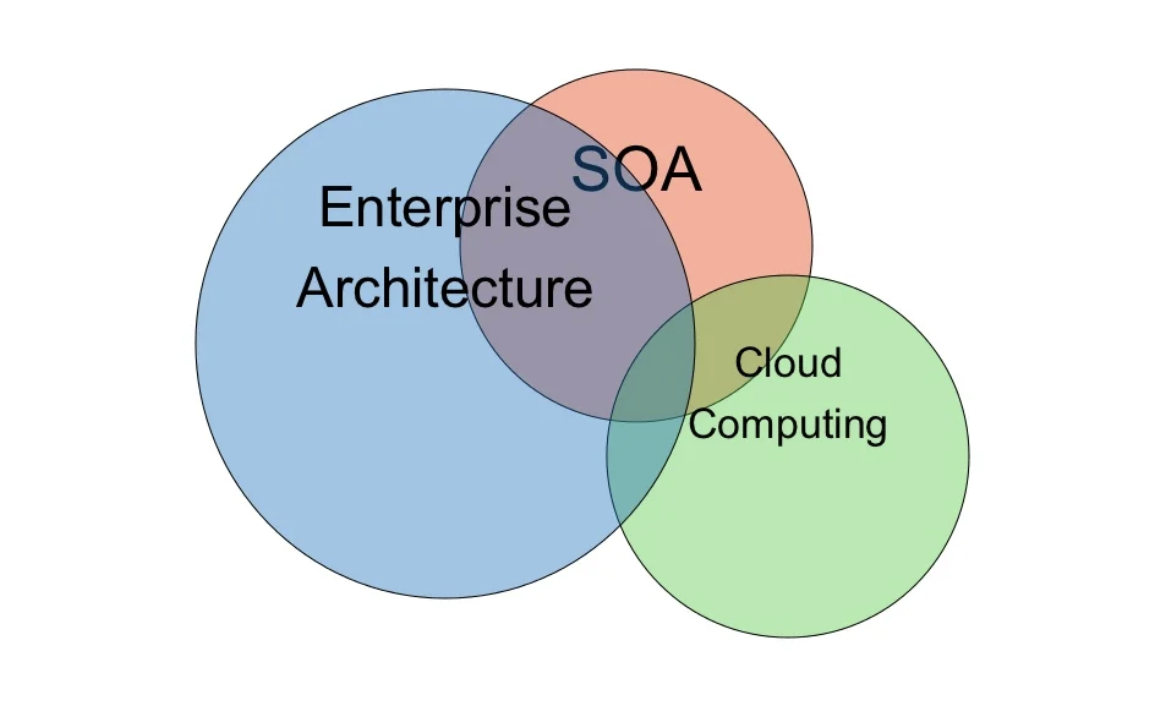
SaaS: Programming a Software as a Service with Laravel and Python.
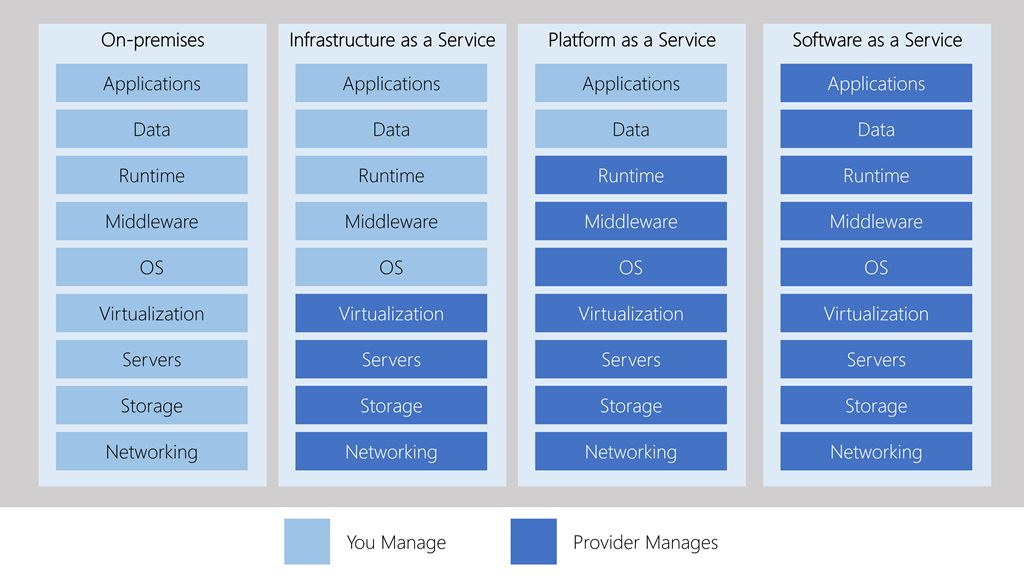
IaaS: Infrastructure as a Service by using Cloud-Computing Instances for Jobs and Workers(Crawlers).
PaaS: Platform as a Service by virtual-cloud instances or dedicated servers for Operating Systems.
Laravel Scout provides a simple, driver based solution for adding full-text search to your Eloquent models. Using model observers, Scout will automatically keep your search indexes in sync with your Eloquent records.
And MongoDB works better in this case then MySQL Databases. MongoDB gives us the collections as API-Request and that is what we need. And by over 1 Billion records on MongoDB Instances are much better by performing and also for search and sorting of Arrays.
I will use private cloud instances over several cloud infrastructure providers like DigitalOcean, VulTR, Google Cloud and Amazon Web Services.
For the own web-crawler we will use Scrapy 2.6.1 with Python 3.0.
Scrapy is a fast high-level web crawling and web scraping framework, used to crawl websites and extract structured data from their pages. It can be used for a wide range of purposes, from data mining to monitoring and automated testing.
Query and QueryID
A Query is a precise request for information retrieval with database and information systems.
That means, we sending a POST-Action to an API-Server or to a Database and getting a QueryID for the searched query.
Why is this necessary?
This will spent us much time for recursive search on database. The time and space is playing a big role in big-data. And we will create search result pages in cache and we will redirect the POST to the cache-server.

Converting a query to ID with a converter from letters to integer value:
Example for a query and queryID: book – 2 15 15 11 – the queryID ist 2151511
Language: English, Type: A=1, B=2, C=3,
Source of Converter
With the converting from letter to integer, we can find out, where to start to search on results. That means we ignore all other letters and searching just on integer values which ist starting with “2” then “215” and recursive search and using dependency.
Step by Step build your own Search Engine with PHP, Python and MongoDB
- Building Front- & Backend Components
– Install Laravel Framework v.9.0 (Link) on LAMP(Linux, Apache, MySQL and PHP) on Ubuntu 20.1
– Install Laravel Scout (Link)
– Install UI-Design in Laravel Directory Structure (Pages – Admin Dashboard HTML Template) - Generete Frontend Pages
– Generete Searchpage UI with Forms- Search Startpage with Search-Form
– Get IP-Adress and DNS-Records of Visitors to find out the country/language of page.
– DE/ENG + QUERY -encoded-> Cache-Server (decoded)
- Search Resultpages with Data sorted by ID (On Step 8 we will create our own Sorting-Algorithm)
- Search Startpage with Search-Form
- Building the Database Architecture & Structure and Laravel Models
– Install MongoDB
– Generate Tables and Collections - Generate Backend Pages
– Login for Backend and Statics for Results and Analytic-Data.
– Cache-Server Options
– other Option Pages - Build your own Web-Crawlers and automatize it:
– In this Step we will build our own crawlers with python.
3 Types of Crawlers:
1. DomainCrawler: Searching new Websites
2. PageCrawler: Adding pages to Cache
3. UpdaterCrawler: Update Pages every Day
– An other Topic about Crawlers: GitHub Link - Get Start-Data from other Pages; API or Crawler*
– Wikipedia, Amazon, Ebay,
– Facebook, Twitter, LinkedIn, Xing
– Booking, Hotel,
– Get urls from open source sites: opendirectories, dmoz, google my business locals etc. - Generete the Cache-Server and Optimize it.
– Generete cache-pages for query requests. - Building a new PageRank Algorithm for Sorting the Results by Domainnames
– Python PageRank Example: GitHub Link
– build own Algorithm with own Factors. In this Step I have a ranking idea! - Setup of Domain on production Server
– Setting up the DNS Records and other Routes.
- Laravel installation via Composer (Laravel v8.83.6 (PHP v7.4.28))
composer create-project laravel/laravel SearchApp
cd SearchApp
php artisan serve— TODO —
Example Website for DomainCrawler:

—— —- —-
Building Laravel Models as Domain URL.
Every URL is a unique address and contains a lot of information. In below you see how a Uniform Resource Locator is builded. A URL gives us the Name of Protocol, the Subdomain, the domain name and the Top Level Domain(TLD).
Example Model: google.com
URL: https://www.google.com
Subdomain: https://www.google.com
Domain name: google
tld: .com
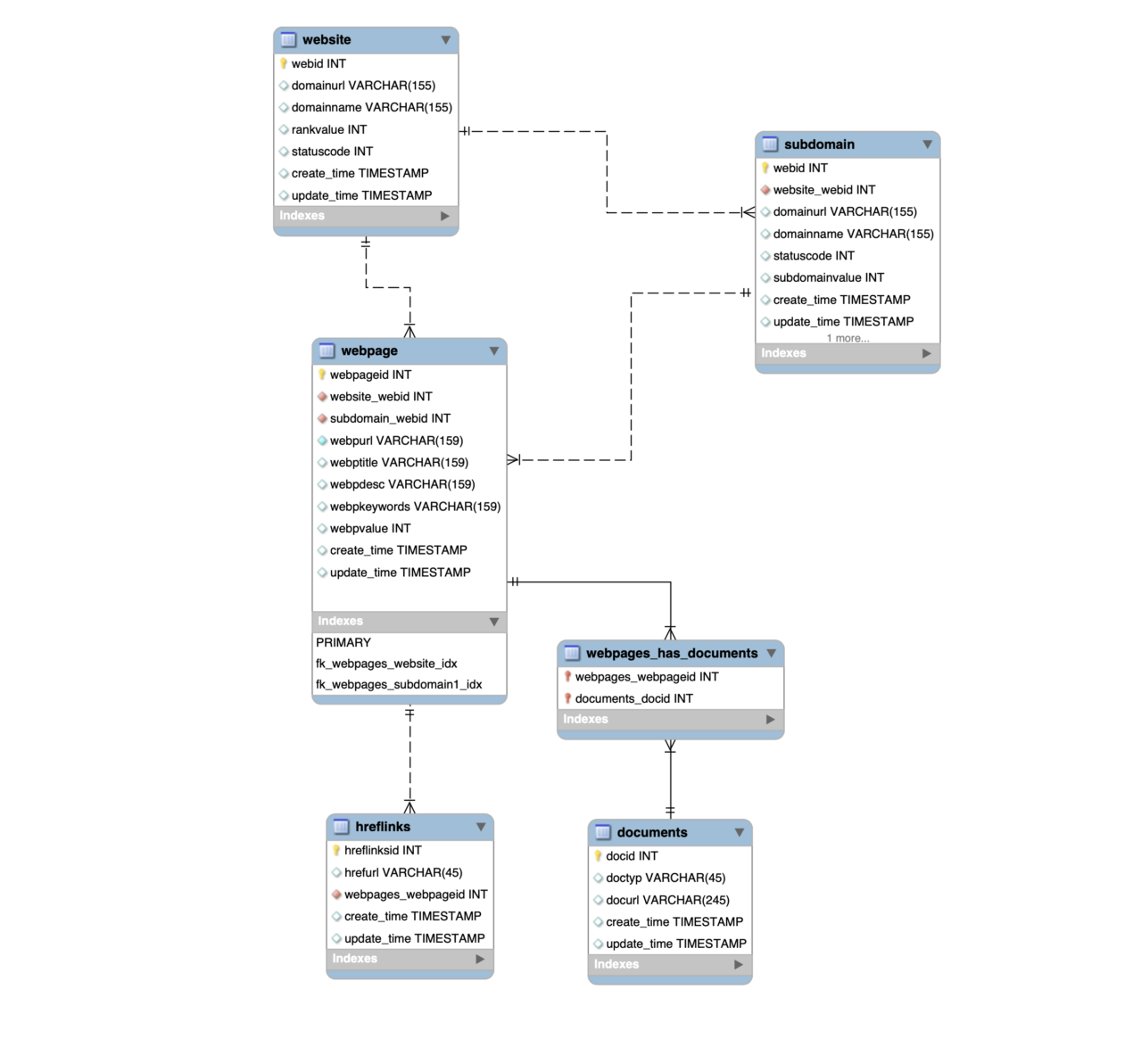
We need a Model with the name Website and generate on cli with following code:
php artisan make:model WebsiteAn example of a Website model is shown below,
<?php
namespace App\Models;
use Illuminate\Database\Eloquent\Model;
class Website extends Model
{
/**
* The primary key associated with the table.
*
* @var string
*/
protected $primaryKey = 'webid';
protected $fillable = ['webpurl', 'webptitle', 'webpdesc', 'webpkeywords', 'webpvalue'];
const CREATED_AT = 'creation_date';
const UPDATED_AT = 'updated_date';
/**
* Get the webpages for the website.
*/
public function webpages()
{
return $this->hasMany(Webpage::class);
}
/**
* Get the subdomains for the website.
*/
public function subdomains()
{
return $this->hasMany(Subdomain::class);
}
}Then we need the other Models like: Webpage, Subdomain, Hreflinks, Documents
php artisan make:model Webpagephp artisan make:model Subdomainphp artisan make:model Hreflinksphp artisan make:model Documents<?php
namespace App\Models;
use Illuminate\Database\Eloquent\Model;
class Webpage extends Model
{
/**
* The primary key associated with the table.
*
* @var string
*/
protected $primaryKey = 'webpageid';
protected $fillable = ['webpurl', 'website_webid', 'subdomain_webid', 'webptitle', 'webpdesc', 'webpkeywords', 'webpvalue', ''];
const CREATED_AT = 'creation_date';
const UPDATED_AT = 'updated_date';
/**
* Get the hreflinks for the webpage.
*/
public function hreflinks()
{
return $this->hasMany(Hreflinks::class);
}
/**
* Get the documents for the webpage.
*/
public function documents()
{
return $this->hasMany(Documents::class);
}
}##TODO
A website has many subdomains. Or inverse: A subdomain belongs to a website. One to many Relationship.
##TODO
##Migration TODO
Uniform Resource Locator(URL)

Domain and TOP LEVEL DOMAINS

OPEN TASKS:
- Crawler DB and DB indices
- Cache-Server with Responsing a ArrayList[99] for every queryID
- Crawlers, Workers, Jobs, Job-Schedulers for generating new or update old content of domain/page
- Search Result Pages with Components; Identify given query and select a Layout for query(Product, Brand, Generic Keywords etc.)
Crawler:
- Types of Crawler: DE, HH, BL,
- Rules of Crawler: find and search in db?
- tf–idf
- Beautiful Soup bs4(Documentation)
In information retrieval, tf–idf (also TF*IDF, TFIDF, TF–IDF, or Tf–idf), short for term frequency–inverse document frequency, is a numerical statistic that is intended to reflect how important a word is to a document in a collection or corpus.[*1]
Last Update: 01.04.2022
*1 Rajaraman, A.; Ullman, J.D. (2011). “Data Mining” (PDF). Mining of Massive Datasets. pp. 1–17. doi:10.1017/CBO9781139058452.002. ISBN 978-1-139-05845-2.